
报告人:王子通 | 2025/12/25
MatchTime 系列论文深度笔记
第一篇论文 MatchTime: Towards Automatic Soccer Game Commentary Generation
核心痛点:消失的“16秒”
在足球视频领域,传统的解说词数据存在严重的音画不同步。由于原始数据大多抓取自实时文字直播,解说词往往比实际进球画面晚了 16.63 秒甚至更多。如果直接用这种“脏数据”训练,AI 只会学会“马后炮”。
第一章:数据治本——如何通过数学实现“降维打击”
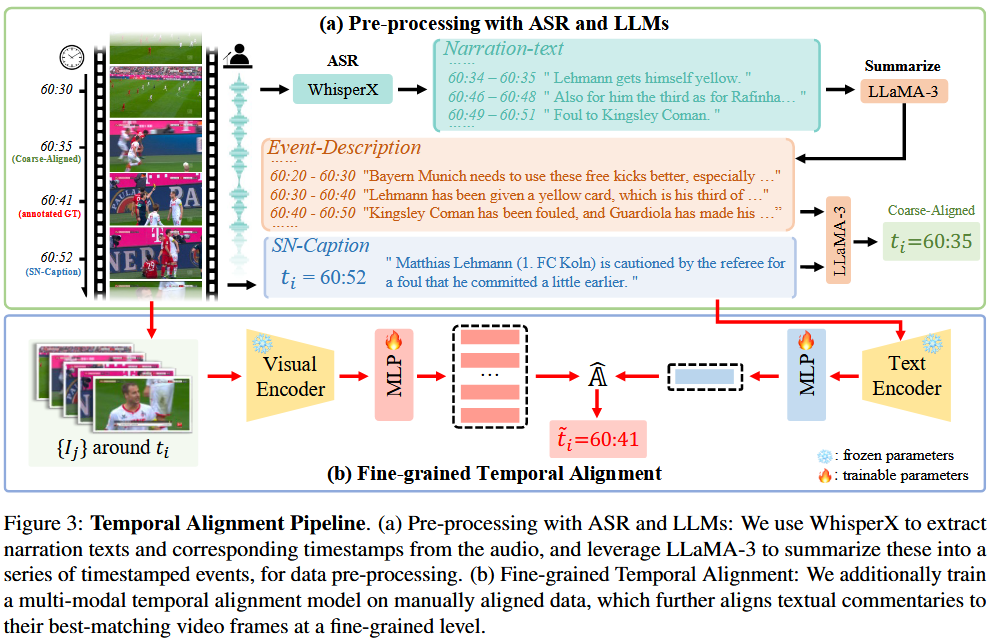
论文的核心贡献在于 Section 3.2 (Temporal Alignment Pipeline),它展示了如何用一套自动化的管线将滞后的文本“拽”回正确的帧。
1. 亲和力矩阵 (Affinity Matrix):连连看的底牌
为了对齐视频帧(Visual Frames)和解说词(Text Captions),作者引入了 Affinity Matrix $\mathbb{A}$。
- 它是怎么来的? 假设视频有$n$ 帧,文本有 $k$ 句,矩阵的大小就是$k \times n$ 。
核心公式推导:亲和力矩阵 (Affinity Matrix)
在计算视频帧 $V_j$ 与文本 $C_i$ 的相似度时,公式表达为:
$$\mathbb{A}[i, j] = \frac{C_i \cdot V_j^T}{||C_i|| \cdot ||V_j|| \cdot \tau}$$
公式拆解:
- 分子 ($C_i \cdot V_j^T$):特征向量的点积,衡量方向一致性。
- 分母 ($||C_i|| \cdot ||V_j||$):$L_2$ 范数归一化,确保计算的是余弦相似度。
- $\tau$:温度参数,用来控制相似度分布的平滑度。
- 深度解析:
- ** 是什么?** 这是向量的 ** 范数**(模长)。之所以要除以它,是为了进行归一化,将计算锁定为余弦相似度。我们只关心文本和画面的“语义方向”是否一致,而不关心特征向量本身的绝对大小。
- 为什么要算这个? 通过寻找矩阵每一行中的最大值(),模型能自动锁死每一句解说词对应的“高光时刻”。
第二章:模型架构——MatchVoice 的“翻译”逻辑
MatchVoice 的本质是一个多模态大模型 (MLLM)。它通过一套精密设计的组件,将视频“翻译”成文字。
1. 为什么视觉编码器 (Visual Encoder) 要冻结?
在架构图中,你会看到视觉部分(如 CLIP 或 Baidu 特征)被打上了“雪花”图标(Frozen)。
- 策略:冻结预训练好的编码器可以保持其强大的通用特征提取能力,同时大幅降低训练成本。
2. Learnable Queries & Attention:精准探测器
- Learnable Queries:它们不是来自视频,而是模型内置的“探测员”。
- 自注意力 (Self-Attention):让这群“探测员”在出发前先开个会,分工合作(比如有的看人,有的看球)。
- 交叉注意力 (Cross-Attention):这是关键!探测员拿着清单去视频特征(超市货架)里取货,把散落在时空中的信息吸收到 Query 向量中。
3. 从投影到生成:MLP 与 Prefix Tokens
- MLP 的翻译官作用:视觉特征与 LLM 的维度往往不匹配。MLP (Projection Layer) 就像转换插头,将视觉特征投影到 LLM 能听懂的空间。
- Prefix Tokens (紫色方块):这是 MLP 输出的唯一成果。它们作为“视觉前缀”喂给 LLM(如 LLaMA-3)。
- 生成逻辑:$C = \Psi_{dec}(\Psi_{proj}(F))$。:。LLM 接收到视觉前缀后,开始顺着这个背景一个词一个词地吐出蓝色的 Commentary Tokens。
第三章:评估的“金标准”——SN-Caption-test-align
为了证明 AI 真的看懂了球,作者没有使用模糊的原始数据进行评估,而是打造了 SN-Caption-test-align。
- 本质:这是对 SoccerNet-Caption 的人工精修版。
- 意义:它不仅是一个数据集,更是一个“公正的考官”。只有在时间戳绝对准确的考卷上拿到高分(如 CIDEr 分数的暴涨),才能证明对齐管线的有效性。
- Baidu 特征最强:实验证明,相比通用的 CLIP,这种在足球领域“深造”过的模型(Baidu Soccer Embeddings)作为视觉编码器效果最佳。
- 数据 > 模型:即便使用基础的 ResNet,只要用了对齐后的 MatchTime 数据集,表现甚至能超越在脏数据上跑的高级模型。
第二篇论文 Towards Universal Soccer Video Understanding
第二篇论文在第一篇论文的基础上提出了SoccerReplay-1988数据集。
并且提出了足球专用的解码器MatchVison
SoccerReplay-19886 Dataset
这篇文章阐述了这个作者是如何做这个数据集的,将视频分为上下两场,从starting at kick off开始。并且采用第一篇文章的MatchTime的对齐方式,通过手动进行人工对齐
对于模型我自己的理解:
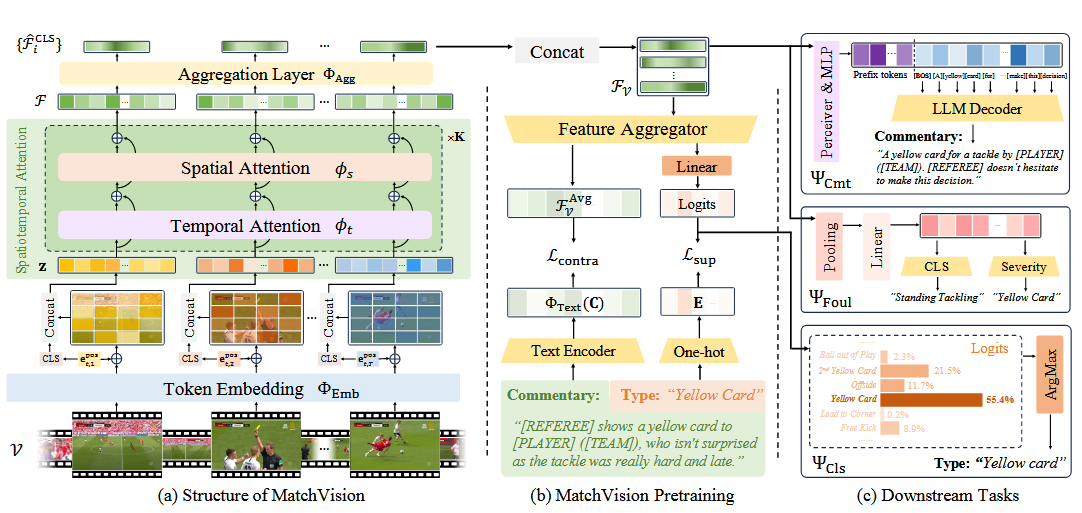
本质上就是一个改进的video transformer
Token Embedding
空间切分: 每一帧图像 $ i $ 被切分成 $ M $ 个不重叠的小方块(Patches)。这就像把一张照片剪成方格阵列。
线性映射 ($\Phi_{Emb}$): 每个小方块被拉平并转换成一个维度为 $D$ 的向量。
双重位置编码 (Position Embedding): 这是关键。
- 空间位置编码 ($e_s^{pos}$):告诉模型这个方块在画面的哪个位置(左上还是右下)。
- 时间位置编码 ($e_t^{pos}$):在处理完整个视频序列后叠加,告诉模型这一组特征属于视频的第几秒。
[CLS] 标记: 每一帧都会加入一个特殊的 [cls] 标记,专门用来汇总这一帧的全局信息。
时空注意力模块
时间自注意力 ($\phi_t$):
- 操作: 只在不同帧的相同空间位置的 Token 之间进行计算。
- 目的: 追踪动作。例如,第1帧里的足球在左边,第2帧里的足球移动到了中间,时间注意力负责捕捉这个“移动”轨迹。
空间自注意力 ($\phi_s$):
- 操作: 只在同一帧内部的不同 Token 之间进行计算。
- 目的: 理解布局。例如,识别出这一帧画面里哪是球员、哪是球门、哪是裁判。
交替堆叠 ($K$ 次): 通过多次交替循环,模型既能看清每一帧的细节,又能理解动作在时间上的逻辑。
聚合层(Aggregation Layer)
在经过复杂的注意力计算后,模型需要把海量的数据“浓缩”成一个简洁的特征向量,供下游任务使用。
- 空间聚合: 利用聚合层 $\Phi_{Agg}$,将每一帧中散落在各个 Patch 里的信息,全部压缩到该帧的
[cls]标记中(得到 $\hat{F}_i^{CLS}$)。 - 最终表示 ($F_V$): 将所有帧的
[cls]标记拼接起来。- 结果: 得到的 $F_V$ 是一个矩阵,它每一行代表一帧的精华,整组矩阵代表了整个视频片段的精华。
预训练层
监督分类 (Supervised Classification, $\mathcal{L}_{sup}$)
- 做法: 将提取出的视频特征 $F_V$ 通过一个时间自注意力层,汇总到一个可学习的
[cls]标记中。 - 计算: 这个标记被输入线性分类器,使用交叉熵损失 (Cross-Entropy Loss) 进行训练。
- 目的: 让模型学会“看图识事”,即直接根据画面判断这是进球还是犯规。
视频-语言对比学习 (Video-Language Contrastive Learning, $\mathcal{L}_{contra}$)
- 做法: 对视频特征进行平均池化得到 $F_V^{Avg}$,同时用文本编码器处理解说词 $C$。
- 创新点: 借鉴了 SigLIP 的损失函数。
- 正样本优化: 针对足球比赛中经常出现高度相似的解说(如“比赛开始”),模型将同一批次中相似度高的文本都视为正样本,增强了鲁棒性。
- 目的: 建立视觉与文本的语义联系,为下游的解说生成任务打好基础。
疑问:
为什么是监督分类?
1. 足球语义的复杂性与明确性
- 语义明确: 足球比赛中的关键事件(如进球、黄牌、换人)都有非常明确的官方定义和边界。
- 监督优势: 监督分类通过使用专家标注的 Event Labels,能直接“教会”模型识别这些高层语义特征。相比之下,无监督学习(如传统的聚类或掩码建模)可能只会让模型学会识别“草坪是绿色的”或“球员在跑动”,而难以自发理解“这是一个越位”这种复杂的逻辑关系。
2. 预训练目标的互补性
根据文本,MatchVision 并不是只用监督学习,而是采用了混合策略:
- 监督分类 ($\mathcal{L}_{sup}$):负责建立视觉特征与官方动作标签的强关联。
- 对比学习 ($\mathcal{L}_{contra}$):这其实具有一定的“弱监督”或“自监督”性质,它通过**视频与解说词(Textual Commentaries)**的匹配,让模型学习更丰富的语言描述能力。
- 结合效果: 监督分类提供了“硬准则”(这是什么动作),而对比学习提供了“软语义”(这个动作怎么描述)。
3. 提升特征的判别力 (Discriminative Power)
- 类内与类间差异: 足球视频中,很多动作看起来极其相似(例如,普通的传球和助攻传球在视觉上可能只有微小区别)。
- 监督的作用: 使用交叉熵损失(Cross-Entropy Loss)的监督训练,会强制模型在特征空间中拉开不同事件类别的距离,从而在下游任务(如犯规识别)中表现得更精准。
4. 行业数据集的现状
- 标注资源: 足球领域拥有如 SoccerNet 这样大规模且高质量的标注数据集。
- 效率考量: 既然已经有了现成的“正确答案(Labels)”,直接使用监督学习进行预训练,比让模型在海量无标注视频中漫无目的地探索(无监督)要高效得多。
什么是cls和cmt
1. CLS (Event Classification - 事件分类)
CLS 是 Classification 的缩写,主要负责“看图识事”,即识别视频中发生了什么特定事件。
- 核心功能: 将输入的足球视频片段归类为预定义的事件标签,例如“进球”、“角球”、“黄牌”或“换人”。
- 实现机制: * 模型会引入一个可学习的 [cls] token,通过时间自注意力机制(Temporal Self-attention)汇总整段视频的时空特征。
- 该特征随后被送入一个线性分类器(Linear Classifier)进行处理。
- 输出结果: 给出各个事件类别的概率分布,通常选取概率最高的一个作为最终判定结果(如:Type: “Yellow card”)。
2. CMT (Commentary Generation - 解说生成)
CMT 是 Commentary 的缩写,主要负责“见图说话”,即生成像专业解说员一样的自然语言描述。
- 核心功能: 自动为视频片段编写一段符合赛况的叙述性文字。
- 实现机制:
- 使用 Perceiver 聚合器 将复杂的视觉特征浓缩,并通过 MLP 映射为前缀嵌入(Prefix Embeddings)。
- 这些视觉嵌入被输入到**大语言模型(LLM)**中,引导 LLM 根据画面内容生成文本。
- 输出结果: 一段完整的句子,例如:“[REFEREE] shows a yellow card to [PLAYER]…”。
下游任务层
预训练完成后,视觉编码器被“冻结”或作为骨干网络,通过不同的预测头 ($\Psi$) 来适配具体任务:
事件分类 ($\Psi_{cls}$)
- 机制: 结构与预训练的监督学习类似,使用时间自注意力聚合特征。
- 训练逻辑: 在冻结视觉编码器的情况下,仅训练线性分类器。
- 输出: 给出视频属于哪种事件(如:角球、黄牌)的概率分布。
解说生成 ($\Psi_{Cmt}$)
-
核心组件: Perceiver 聚合器 + MLP + LLM(大语言模型)。
-
流程: 1. Perceiver 将海量的视觉特征压缩。
\2. MLP 将其映射为 LLM 能听懂的“前缀嵌入(Prefix Embeddings)”。
\3. LLM 根据这些“视觉前缀”像写作文一样生成解说词。
-
损失函数: 使用负对数似然损失(Next-Token Prediction)。
犯规识别 ($\Psi_{Foul}$)
- 输入: 足球比赛中常见的**多视角(Multi-view)**视频。
- 处理: 使用池化技术(Max/Avg Pooling)将多视角特征整合为一个向量。
- 双任务输出: 使用一个共享的 MLP 接两个分类器,同时预测:
- 犯规类型(如:铲球犯规、手球等,共 8 种)。
- 严重程度(如:口头警告、黄牌、红牌等,共 4 级)。
为什么要使用MLP
实现跨模态的特征对齐,不需要更强大的模型,简单的MLP足够胜任模态对齐工作
实验部分
基于他上面自己的soccer Replay 1988数据集进行实验
MatchVision在分类这个任务是达到了**82.5%**的准确率
证明对比学习比监督学习的效果更好
并且MatchVision在foul recongition方面,即使冻结了视觉编码器,也和顶尖模型不相上下
最后部分
使用了LoRA技术调教LLM
这篇论文有三个比较大的贡献
新资源:造出了迄今为止最大的足球数据集 SoccerReplay-1988。
新模型:开发了专门针对足球时空特征的编码器 MatchVision。
新标杆:在分类、解说、犯规识别等多个任务上都达到了世界领先水平 (SOTA)。
Multi-Agent System for Comprehensive Soccer Understanding
引言
论文在引言部分介绍了现在的研究在足球理解研究的一些挑战
在推理任务上比较的局限(局限于视觉分析而缺少了推理)
以及模型过于的碎片化和专家化
这篇文章主要有四个贡献
构建了 SoccerWiki 知识库:这是第一个大规模的多模态足球知识库,集成了关于球员、球队、裁判和场地的丰富领域知识,旨在支持知识驱动的推理任务 。该库包含 9,471 名球员、266 支球队、202 名裁判和 235 个场地的详细信息 。
建立了 SoccerBench 基准测试集:这是目前最大且最全面的足球领域专项基准 。它通过自动化的数据策划和人工验证构建,包含约 1 万个多模态(文本、图像、视频)选择题对,涵盖了背景知识、比赛局势识别、犯规识别等 13 项不同的足球分析任务 。
开发了 SoccerAgent 多智能体系统:这是一种新型的多智能体协作系统,通过将复杂的足球问题分解为多个可执行的子任务来解决问题 。它利用了 SoccerWiki 的领域专家知识,并能够调用 18 个专项工具进行协作推理 。
进行了广泛的评估与对比:作者在 SoccerBench 上将 SoccerAgent 与 11 种代表性的多模态大语言模型(MLLMs,如 GPT-4o、Claude 3.7、Gemini 2.0 等)进行了深入对比 。评估结果突显了该智能体系统在处理复杂、知识密集型足球任务中的优越性 。101
介绍soccerBench
| 维度 | 包含任务 (Index) | 考查重点 |
|---|---|---|
| 纯文本推理 (TextQA) | Q1 背景知识, Q2 比赛局势 | 考查模型是否掌握了球员历史、转会、比赛战术等“足球常识”。 |
| 图像视觉感知 (ImageQA) | Q3 相机状态分类, Q4 图片背景知识, Q5 球衣号码识别, Q6 比分与时间识别 | 考查模型对单张转播截图的解析力,例如识别“这是哪场比赛”、“这是几号球员”。 |
| 视频动态分析 (VideoQA) | Q7 相机切换, Q8 回放定位, Q9 动作分类, Q10/Q11 评论生成与理解, Q12 球衣颜色识别, Q13 多视角犯规识别 | 最难的部分。考查模型能否理解动作的连贯性,并根据规则做出裁判级别的判断(如 Q13 判定是否犯规)。 |
研究动机
作者认为目前足球AI时效性不足,评价碎片化
作者构建了SoccerWIKI,并且在此基础上构建了SoccerBench
Data Curation
团队采用不同的策略生成原始问答对(模版生成,大模型生成)
并且转化成四选一的选择题
最后通过自动化合成再经过人工筛选,组成了SoccerBench
SoccerAgent
论文的核心部分
基于DeepSeek-V3的主模块协同工作
规划者 ($\mathcal{A}_{plan}$):负责“思考”。它接收问题后,并不直接回答,而是分析需要哪些步骤,从工具包里挑选出最合适的工具链。
执行者 ($\mathcal{A}_{exec}$):负责“动手”。它按照规划好的顺序,一个接一个地运行工具。每一步都会参考之前的执行历史($\mathcal{H}_{i}$),从而实现上下文感知的自适应调整。
ToolBox
12 个足球专项工具:
基础分析:动作分类器、评论生成 。
检索专家:比赛搜索、比赛历史/信息检索、人脸识别(从 SoccerWiki 匹配球员) 。
感知专家:相机状态检测、球衣号码/颜色识别、比分和时间识别 。
高级裁判:犯规识别(通过多视角投票机制模拟 VAR)和回放定位 。
6 个通用解析工具:
包括帧选择(将视频转为关键帧)、语义分割(定位特定物体)、实体搜索和文本检索等 。
实验部分
比较重点的:我认为是容错能力
自主调整: 执行者 ($\mathcal{A}_{exec}$) 在发现第一步失败后,并没有卡死,而是根据历史上下文自主调整策略,改用“比赛搜索”工具成功找回了所需信息 。